
Artificial Intelligence has transformed the semiconductor industry, driving demand for increasingly powerful accelerators capable of handling massive neural networks and data-intensive workloads. While compute units such as GPUs, TPUs, and NPUs receive significant attention, the efficiency of these accelerators depends heavily on how data moves across the chip. As AI models grow larger and more complex, traditional communication methods struggle to keep pace. This challenge has made Network-on-Chip (NoC) architectures a fundamental component of modern AI accelerator design.
Why AI Accelerators Need Network-on-Chip Architectures
Modern AI workloads involve thousands of processing elements operating simultaneously. These processing units continuously exchange activations, weights, and intermediate results during training and inference. Traditional interconnect approaches such as shared buses and crossbars become inefficient as system complexity increases.
Network-on-Chip architectures address this problem by introducing a scalable communication framework that connects compute cores, memory blocks, and specialized AI engines through a network of routers and links. Instead of relying on direct point-to-point connections, data is transmitted as packets across the network, enabling efficient communication even in highly parallel systems.
For AI accelerators, NoCs provide the scalability and bandwidth necessary to support the growing computational demands of large language models, computer vision systems, and generative AI applications.
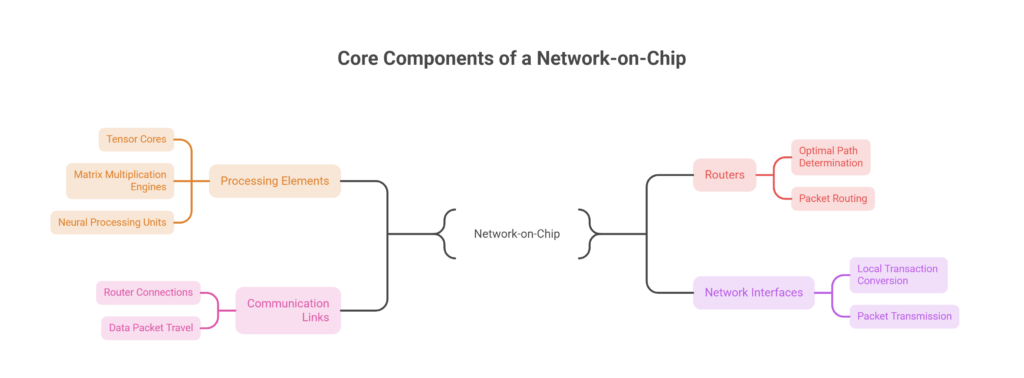
Core Components of a Network-on-Chip
A NoC functions similarly to a miniature data network integrated within a chip. Several key components work together to enable efficient communication.
Processing Elements (PEs)
These include AI compute units such as tensor cores, matrix multiplication engines, and neural processing units that perform the actual computations.
Routers
Routers manage packet movement across the network and determine the optimal path to the destination.
Communication Links
Links connect routers and serve as the physical channels through which data packets travel.
Network Interfaces
These interfaces convert local transactions from compute units into packets that can be transmitted through the NoC.
Together, these components create a structured communication fabric that allows thousands of processing elements to exchange data efficiently.
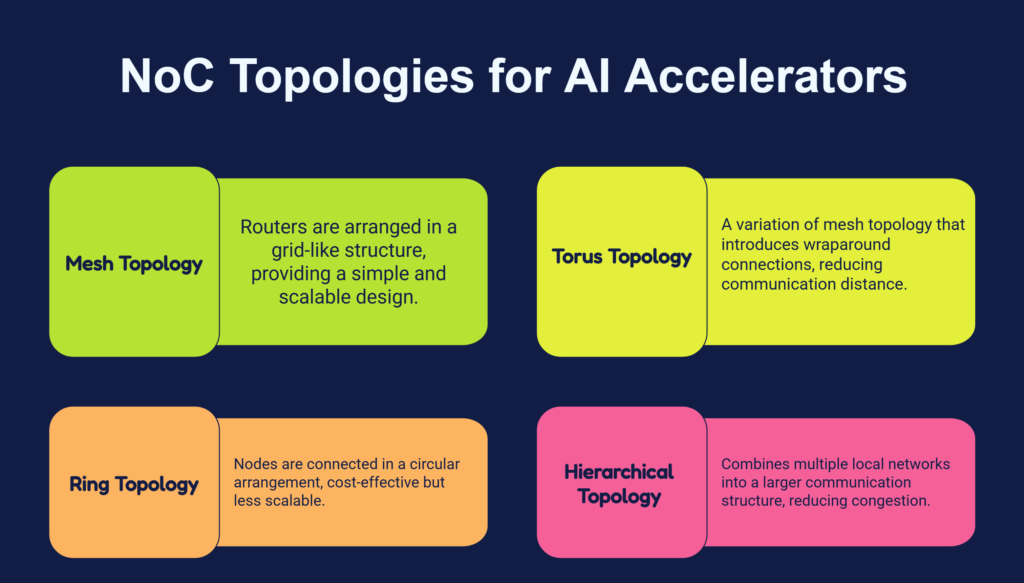
Popular NoC Topologies for AI Accelerators
The topology of a NoC determines how routers are interconnected and significantly influences performance, latency, and scalability.
Mesh Topology
The most widely used NoC topology in AI accelerators. Routers are arranged in a grid-like structure, providing a simple and scalable design that aligns well with chip layouts.
Torus Topology
A variation of mesh topology that introduces wraparound connections, reducing communication distance and improving network efficiency.
Ring Topology
A cost-effective architecture where nodes are connected in a circular arrangement. While simpler to implement, it is less scalable for large AI systems.
Hierarchical Topology
Large AI accelerators often use hierarchical networks that combine multiple local networks into a larger communication structure, reducing congestion and improving scalability.
Among these options, mesh and hierarchical architectures are currently the most common in commercial AI accelerators.
Key Design Challenges in AI-Focused NoCs
As AI workloads continue to scale, NoC designers face several critical challenges.
Bandwidth Demand
Modern AI models require enormous data movement between processing elements and memory systems. The NoC must deliver sufficient bandwidth without becoming a performance bottleneck.
Latency Reduction
Many AI applications, particularly real-time inference systems, require rapid communication. Minimizing packet transmission delays is essential for achieving low response times.
Congestion Management
Simultaneous data requests from multiple compute units can create network hotspots. Advanced routing and traffic management techniques are required to maintain performance.
Power Efficiency
Data movement often consumes more energy than computation itself. Designing energy-efficient NoCs is therefore critical for reducing overall accelerator power consumption.
Addressing these challenges is essential for maximizing the performance of next-generation AI hardware.

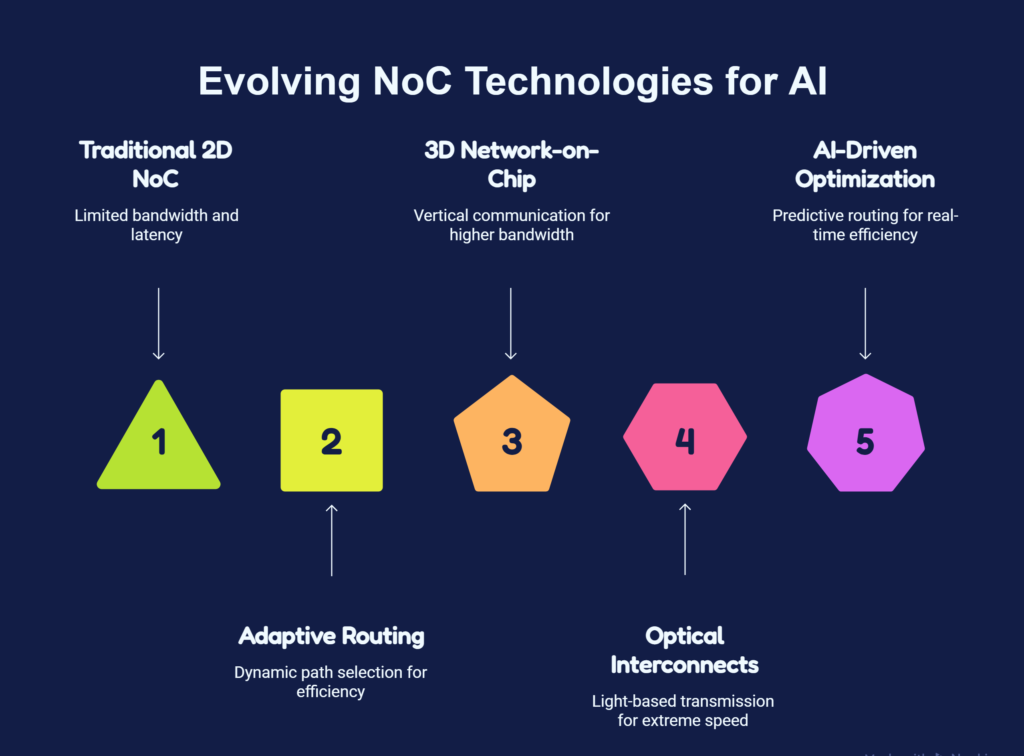
Emerging Innovations in NoC Design
To meet future AI requirements, researchers and semiconductor companies are exploring several advanced NoC technologies.
Adaptive Routing
Modern NoCs increasingly use intelligent routing algorithms that dynamically select paths based on current traffic conditions, reducing congestion and improving throughput.
3D Network-on-Chip
As 3D chip stacking becomes more common, NoCs are expanding beyond two-dimensional layouts. Vertical communication through stacked dies significantly increases bandwidth while reducing latency.
Optical Interconnects
Silicon photonics enables data transmission using light instead of electrical signals. Optical NoCs offer the potential for extremely high bandwidth and improved energy efficiency.
AI-Driven Traffic Optimization
Machine learning techniques are being investigated to predict traffic patterns and optimize routing decisions in real time.
These innovations are expected to play a major role in future AI accelerator architectures.
The Future of NoCs in AI Hardware
The performance of future AI systems will depend not only on computational power but also on communication efficiency. As models continue to grow in size and complexity, data movement is becoming one of the primary constraints in accelerator design.
Network-on-Chip architectures provide the scalable foundation needed to connect thousands of compute units, memory resources, and specialized processing engines. Emerging technologies such as hierarchical NoCs, 3D integration, adaptive routing, and photonic communication will further enhance performance and efficiency.
Conclusion
As AI workloads continue to push the limits of semiconductor technology, efficient on-chip communication has become just as important as computational capability. Network-on-Chip architectures provide the high-bandwidth, scalable, and energy-efficient communication framework required by modern AI accelerators. By enabling seamless data movement across thousands of processing elements, NoCs are emerging as the critical infrastructure that will power the next generation of intelligent computing systems.